Shown in proof packet
Slack approval gate: approval_status: approved, approver U0AKT8RE8N9, and callback evidence from Slackbot via app.oncallzero.com.
Shown in proof packet
Signed webhook and Slack signature validation: Prometheus accepted only with configured headers; Slack signature is marked valid with clock_skew_seconds=0.
Implemented in this run
Action guard: executed tool matched approved tool rollback_k8s_deployment, target namespace matched oncallzero-workloads, and execution proceeded without a permission-denied log.
Implemented in this run
Namespace/action scope: RBAC evidence permits deployment patch/update plus pod list/get/delete in the owned workload namespace. That caps this packet to the shown cluster and namespace.
Shown in proof packet
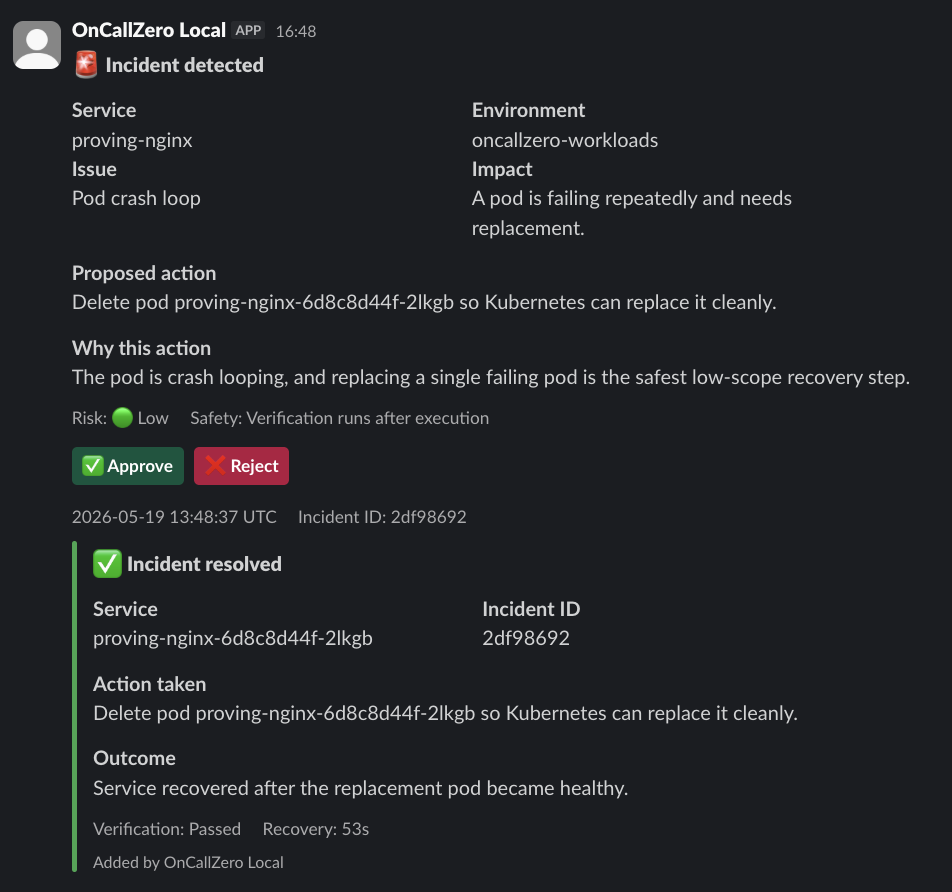
Verification verdict: deployment returned to 2/2 ready, rollout complete, active ReplicaSet proving-nginx-584f49ffbd, verification passed.
Shown in proof packet
Audit IDs: five entries cover incident opened, action proposal, approval request, approval decision, and tool call. Full raw audit JSON is not exposed as a public artifact.
Implemented in this run
Deny-by-default posture is evidenced for inbound webhooks: no API key returns 401, correct API key without webhook secret returns 403, signed webhook returns 202.
Pending proof
No kill-switch artifact is present in this public packet. No broad multi-tenant, multi-cluster, or customer-production safety claim is made here.
{kind=link}